tmp_dir = idb.get_default_data_root()Nonlinear Benchmark Workshop Datasets
Fill in a module description here
Wiener Hammerstein Dataset
def plot_workshop_data(dataset_function,max_sequences=3):
train_val, test = dataset_function(always_return_tuples_of_datasets=True)
fig, axs = plt.subplots(2, 1, figsize=(12, 8), sharex=True)
# Plot training/validation data
for i, data in enumerate(train_val[:max_sequences]):
axs[0].plot(data.u, alpha=0.7, label=f'Train {i+1}')
axs[1].plot(data.y, alpha=0.7, label=f'Train {i+1}')
# Plot test data
for i, data in enumerate(test[:max_sequences]):
axs[0].plot(data.u, ls='--', alpha=0.8, label=f'Test {i+1}')
axs[1].plot(data.y, ls='--', alpha=0.8, label=f'Test {i+1}')
axs[0].set_title('Input Sequences')
axs[0].set_ylabel('Amplitude')
axs[0].legend()
axs[1].set_title('Output Sequences')
axs[1].set_xlabel('Sample')
axs[1].set_ylabel('Amplitude')
axs[1].legend()
plt.tight_layout()
plot_workshop_data(nonlinear_benchmarks.WienerHammerBenchMark)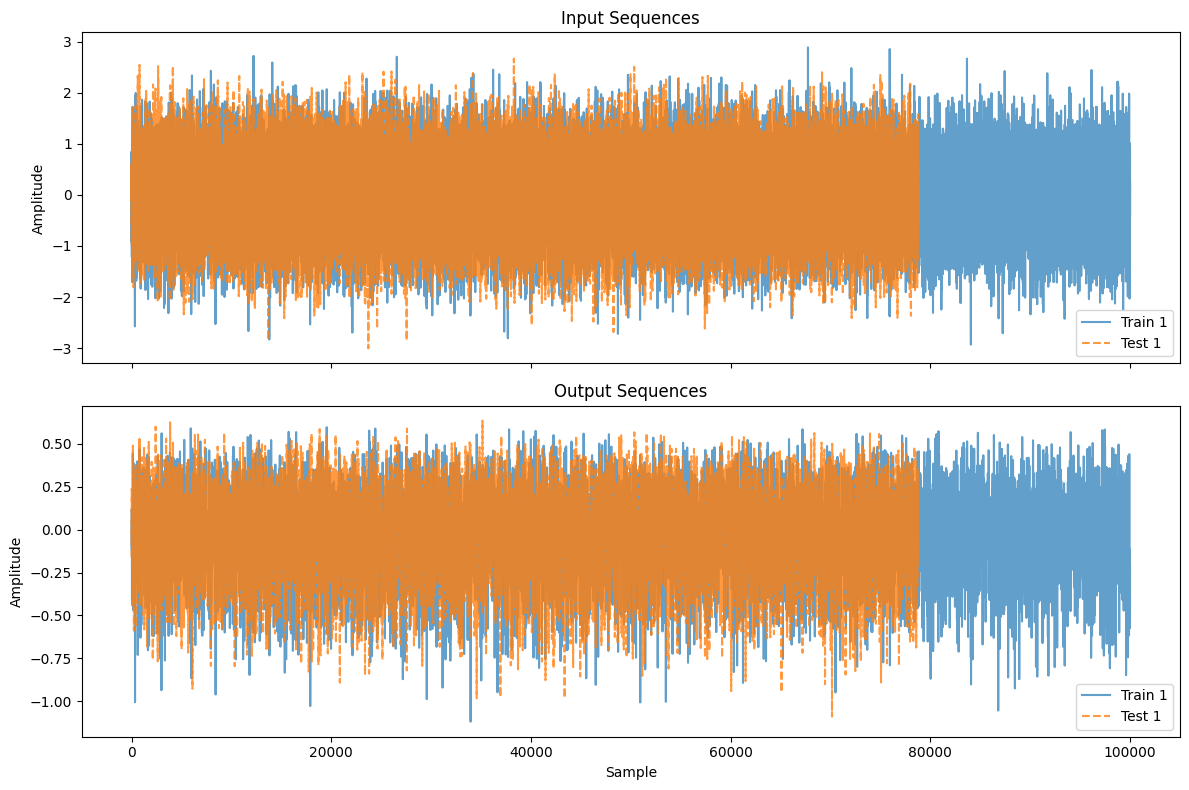
dl_wiener_hammerstein
dl_wiener_hammerstein (save_path:pathlib.Path, force_download:bool=False, save_train_valid:bool=True, split_idx:int=80000)
| Type | Default | Details | |
|---|---|---|---|
| save_path | Path | directory the files are written to, created if it does not exist | |
| force_download | bool | False | force download the dataset |
| save_train_valid | bool | True | save unsplitted train and valid datasets in ‘train_valid’ subdirectory |
| split_idx | int | 80000 | split index for train and valid datasets |
| Returns | None |
dl_wiener_hammerstein(tmp_dir / 'wh' )
dl_wiener_hammerstein(tmp_dir / 'wh' ,save_train_valid=False)result = idb.run_benchmark(
spec=BenchmarkWH_Simulation,
build_model=idb._dummy_build_model
)
result['metric_score']Building model with spec: BenchmarkWH_Simulation, seed: 274805046247.20421449579186result = idb.run_benchmark(
spec=BenchmarkWH_Prediction,
build_model=idb._dummy_build_model
)
result['metric_score']Building model with spec: BenchmarkWH_Prediction, seed: 1203809552241.88528087531387Silverbox Dataset
plot_workshop_data(nonlinear_benchmarks.Silverbox)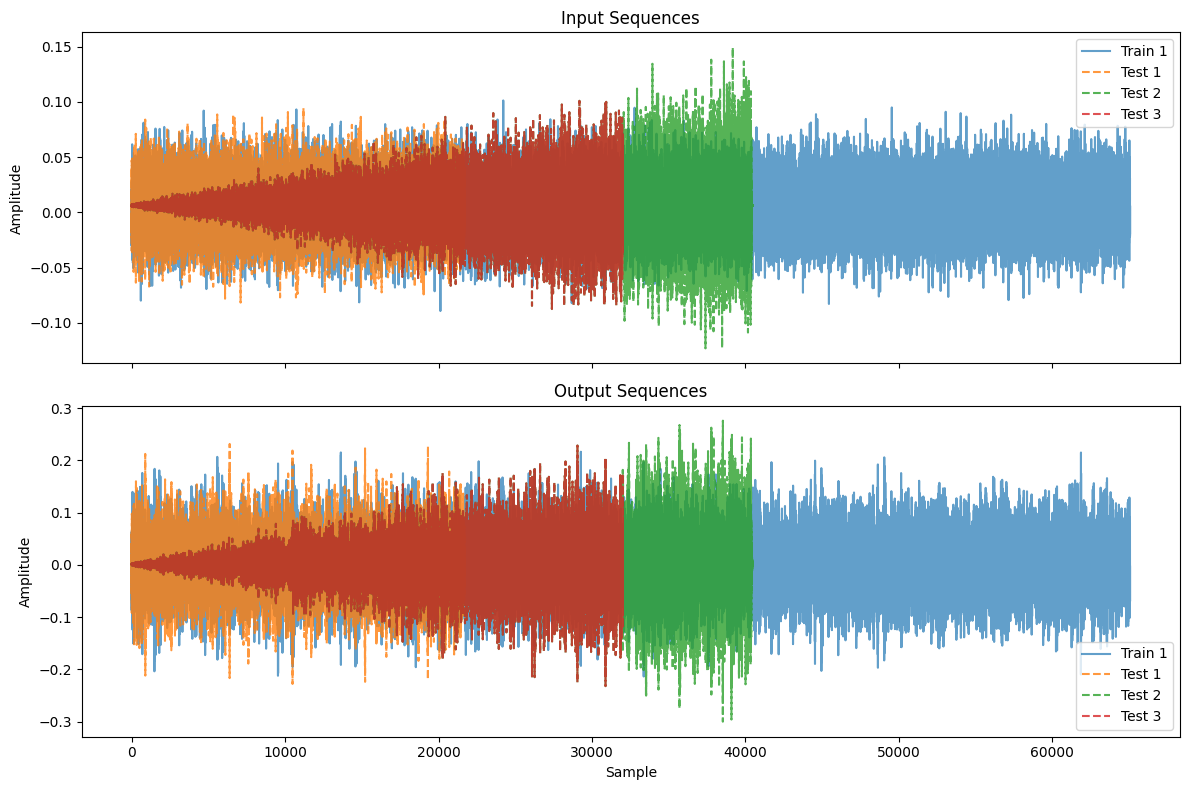
dl_silverbox
dl_silverbox (save_path:pathlib.Path, force_download:bool=False, save_train_valid:bool=True, split_idx:int=50000)
| Type | Default | Details | |
|---|---|---|---|
| save_path | Path | directory the files are written to, created if it does not exist | |
| force_download | bool | False | force download the dataset |
| save_train_valid | bool | True | save unsplitted train and valid datasets in ‘train_valid’ subdirectory |
| split_idx | int | 50000 | split index for train and valid datasets |
| Returns | None |
dl_silverbox(tmp_dir / 'silverbox')result = idb.run_benchmark(
spec=BenchmarkSilverbox_Simulation,
build_model=idb._dummy_build_model
)
result['metric_score']Building model with spec: BenchmarkSilverbox_Simulation, seed: 66584970850.27112906124001result = idb.run_benchmark(
spec=BenchmarkSilverbox_Prediction,
build_model=idb._dummy_build_model
)
result['metric_score']Building model with spec: BenchmarkSilverbox_Prediction, seed: 101472204545.73670007667041Cascaded Tanks Dataset
plot_workshop_data(nonlinear_benchmarks.Cascaded_Tanks)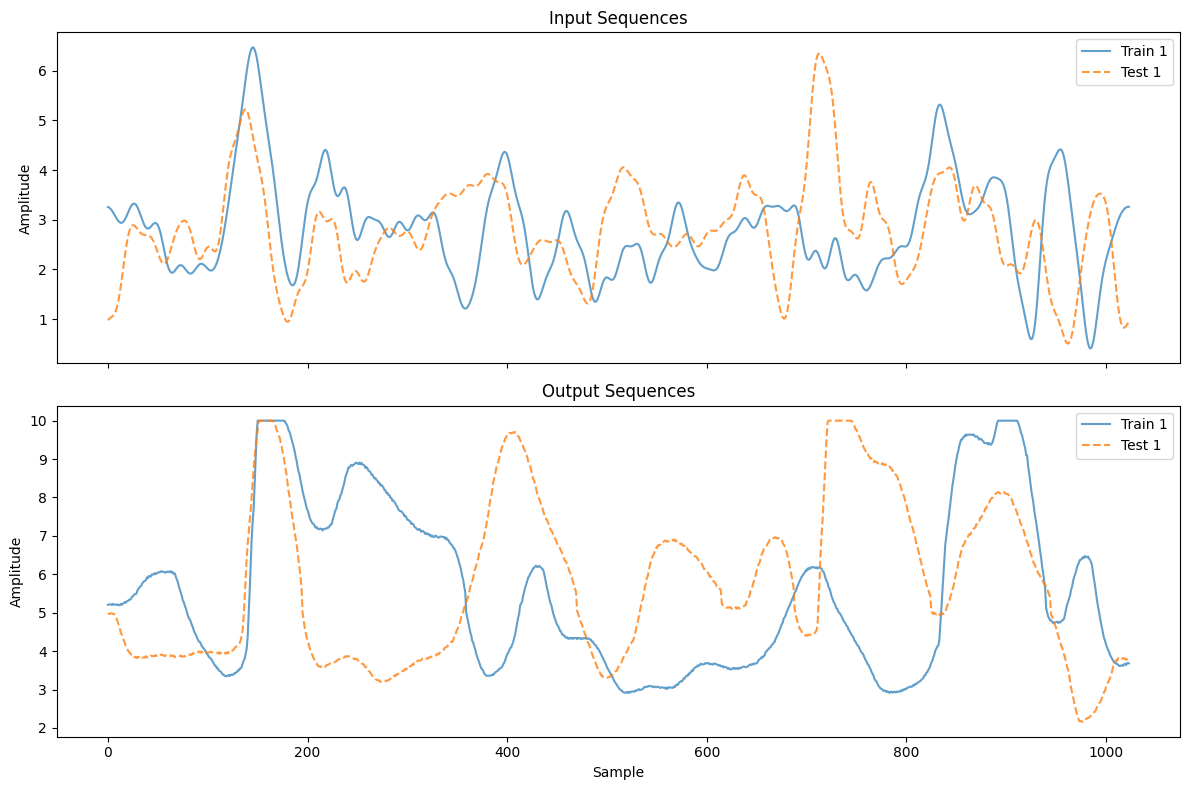
dl_cascaded_tanks
dl_cascaded_tanks (save_path:pathlib.Path, force_download:bool=False, save_train_valid:bool=True, split_idx:int=160)
| Type | Default | Details | |
|---|---|---|---|
| save_path | Path | directory the files are written to, created if it does not exist | |
| force_download | bool | False | force download the dataset |
| save_train_valid | bool | True | save unsplitted train and valid datasets in ‘train_valid’ subdirectory |
| split_idx | int | 160 | split index for train and valid datasets |
| Returns | None |
dl_cascaded_tanks(tmp_dir / 'cascaded_tanks' )result = idb.run_benchmark(
spec=BenchmarkCascadedTanks_Simulation,
build_model=idb._dummy_build_model
)
result['metric_score']Building model with spec: BenchmarkCascadedTanks_Simulation, seed: 21256910366.190198457201898result = idb.run_benchmark(
spec=BenchmarkCascadedTanks_Prediction,
build_model=idb._dummy_build_model
)
result['metric_score']Building model with spec: BenchmarkCascadedTanks_Prediction, seed: 39524148536.087247931804716EMPS Dataset
plot_workshop_data(nonlinear_benchmarks.EMPS)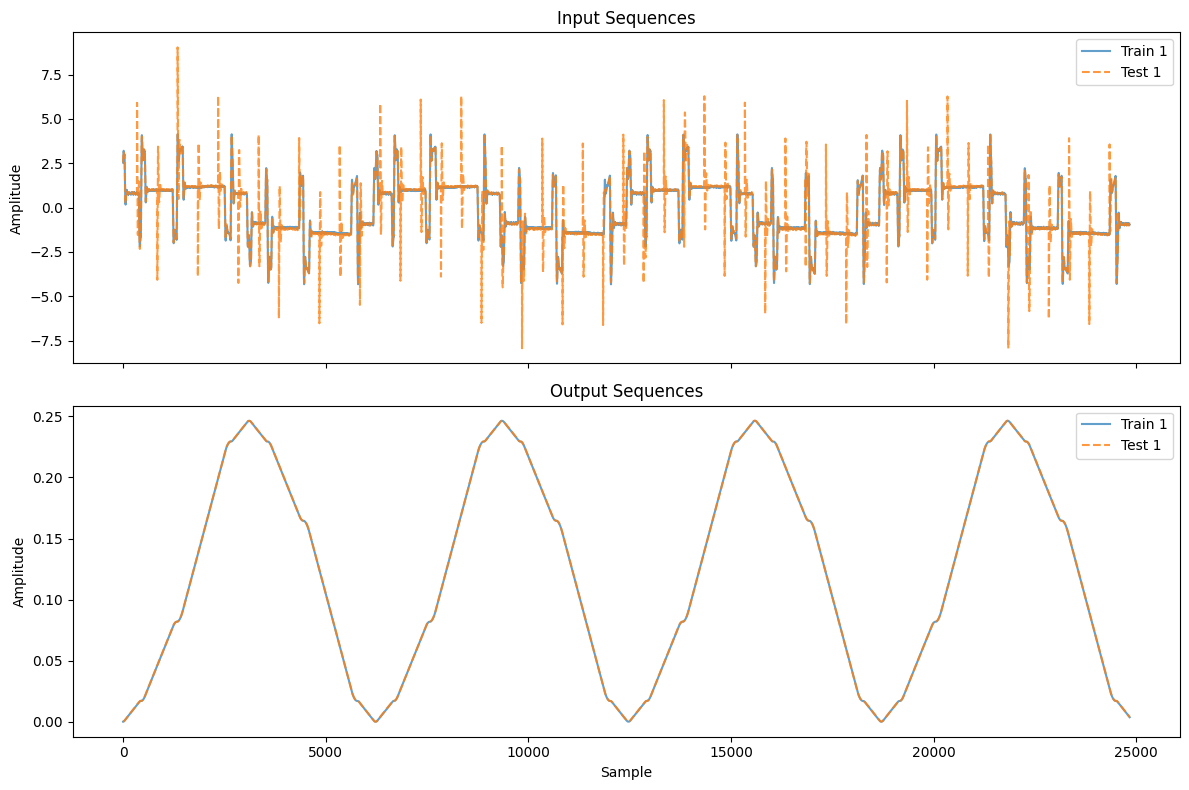
dl_emps
dl_emps (save_path:pathlib.Path, force_download:bool=False, save_train_valid:bool=True, split_idx:int=18000)
| Type | Default | Details | |
|---|---|---|---|
| save_path | Path | directory the files are written to, created if it does not exist | |
| force_download | bool | False | force download the dataset |
| save_train_valid | bool | True | save unsplitted train and valid datasets in ‘train_valid’ subdirectory |
| split_idx | int | 18000 | split index for train and valid datasets |
| Returns | None |
dl_emps(tmp_dir / 'emps')result = idb.run_benchmark(
spec=BenchmarkEMPS_Simulation,
build_model=idb._dummy_build_model
)
result['metric_score']Building model with spec: BenchmarkEMPS_Simulation, seed: 159203475148.94509370511423result = idb.run_benchmark(
spec=BenchmarkEMPS_Prediction,
build_model=idb._dummy_build_model
)
result['metric_score']Building model with spec: BenchmarkEMPS_Prediction, seed: 1758391957127.00285207332765Noisy Wiener Hammerstein
dl_noisy_wh
dl_noisy_wh (save_path:pathlib.Path, force_download:bool=False, save_train_valid:bool=True)
the wiener hammerstein dataset with process noise
| Type | Default | Details | |
|---|---|---|---|
| save_path | Path | directory the files are written to, created if it does not exist | |
| force_download | bool | False | force download the dataset |
| save_train_valid | bool | True | save unsplitted train and valid datasets in ‘train_valid’ subdirectory |
| Returns | None |
dl_noisy_wh(tmp_dir / 'noisy_wh' )results = result = idb.run_benchmark(
spec=BenchmarkNoisyWH_Simulation,
build_model=idb._dummy_build_model
)
results['metric_score']Building model with spec: BenchmarkNoisyWH_Simulation, seed: 3771735968104.1542183129001results = result = idb.run_benchmark(
spec=BenchmarkNoisyWH_Prediction,
build_model=idb._dummy_build_model
)
results['metric_score']Building model with spec: BenchmarkNoisyWH_Prediction, seed: 42189510281.6161143620699Parallel Wienerhammerstein
#ToDoF16
#ToDoCoupled Electric Drives
plot_workshop_data(nonlinear_benchmarks.CED)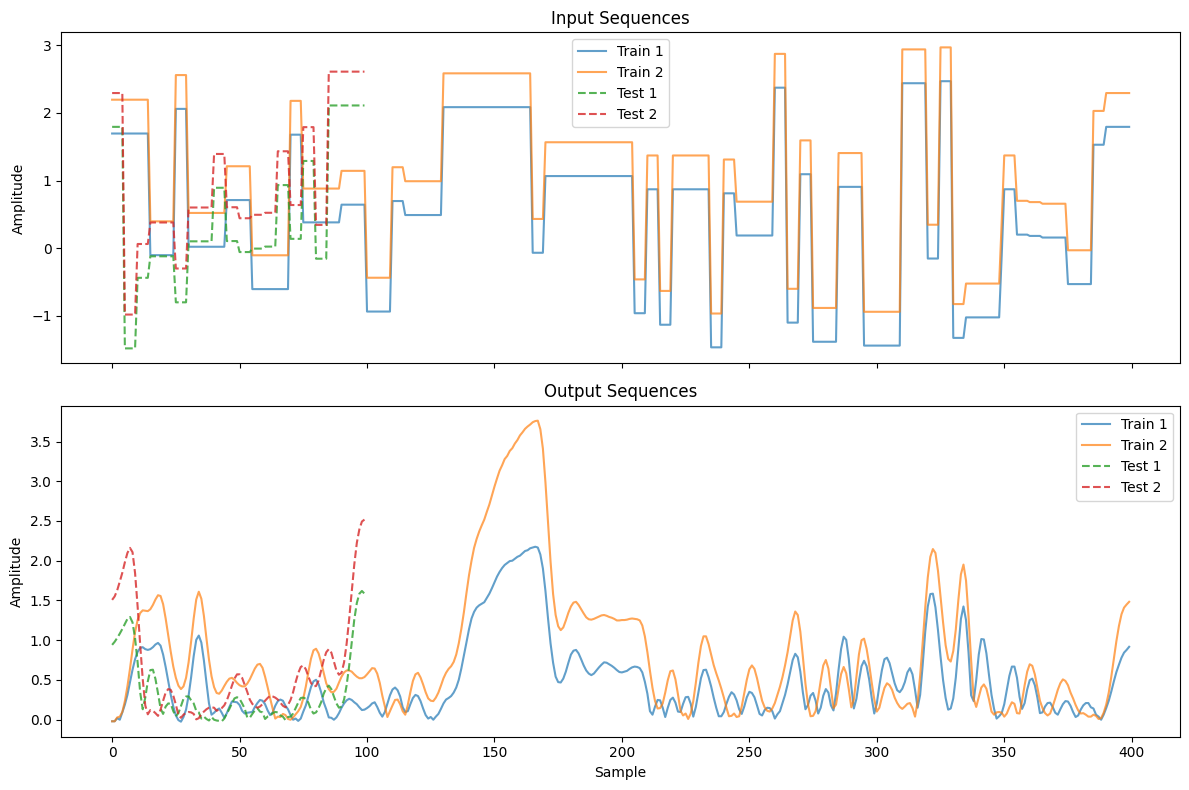
dl_ced
dl_ced (save_path:pathlib.Path, force_download:bool=False, save_train_valid:bool=True, split_idx:int=300)
| Type | Default | Details | |
|---|---|---|---|
| save_path | Path | directory the files are written to, created if it does not exist | |
| force_download | bool | False | force download the dataset |
| save_train_valid | bool | True | save unsplitted train and valid datasets in ‘train_valid’ subdirectory |
| split_idx | int | 300 | split index for train and valid datasets |
| Returns | None |
dl_ced(tmp_dir / 'ced' )result = idb.run_benchmark(
spec=BenchmarkCED_Simulation,
build_model=idb._dummy_build_model
)
result['metric_score']Building model with spec: BenchmarkCED_Simulation, seed: 7508520110.5816430221160263result = idb.run_benchmark(
spec=BenchmarkCED_Prediction,
build_model=idb._dummy_build_model
)
result['metric_score']Building model with spec: BenchmarkCED_Prediction, seed: 41239959340.49837518028637195